纠结了好久不知道起个什么名字,就这个吧,不说深也不说浅,就说
K-means基础的东东吧。
K-means介绍
K-means是一种常见的数据挖掘算法,主要用于聚类分析,是机器学习中无监督学习的一种,也是很有代表性的一种。K-means分为离线和实时两类算法,算法基本一致,只不过离线是常规的离线数据分析方式,实时则是对应于实时流的分析。
k-means算法描述
假设我们有n个特征向量点x1, x2, …, xn,并且我们知道他们落于k( k < n )个簇中。令mi为簇i中向量点的均值。如果簇是很好的分开的,我们可以使用最小距离来把它们分至不同簇。也就是我们可以说当|| x - mi ||为最小值时,x属于簇i。这表明可以用以下算法来找到其k个均值:
决定聚簇的初始中心点 m1, m2, ..., mk
Until k个均值没有任何变化
使用估计的均值点来分类所有的样本点
For i from 1 to k
用簇i中所有样本点的均值来作为新的mi
end_for
end_until
一种简单的k-means实现是划分到k个簇中样本点距中心点距离平方和的最小值来作为其终止条件,这种算法可以看作是一种贪心算法,它也有缺点。 这种方式没有指定初始中心点,通常解决方案时随机选取k个样本点作为初始的中心点。
- 结果的质量很依赖初始质心的选取,并且会经常发生一个不太好的划分被当作结果。标准的解决办法是尝试不同的初始质心来多次运行程序,综合他们的结果。
- 当然也有可能发生的情况是靠近mi的样本点的个数为0,因此mi也没有办法更新,最终得到了空簇。这种情况需要我们处理,当然,可以简单的选择忽略。
-
结果依赖对 x - mi 的度量。常规的解决方案时归一化他们的标准差。 - 结果依赖簇个数k的值。
最后一个问题是最麻烦的,因为我们根本不知道样本点中到底存在多少聚簇。我们不知道聚簇的结果是不是正确的或者说是不是最优的。
模糊k-means
K-means程序生成的聚簇有时候被称作“硬聚簇”或者是“绝对聚簇”,因为每个特征向量x要么属于要么不属于一个聚簇。这和“软聚簇”或者叫“模糊聚簇”是截然不同的,在这种聚簇中,x可以在一定程度上属于每一个聚簇。
Dunn和Bezdek的模糊k-means允许每个特征向量有个表示对聚簇i的从属关系的度:
- 决定初始质心m1, m2,…, mk
- Until 任何质心都不在变化
-
用估计质心找到xj对聚簇i的从属关系度,例如,如果a(j,i) = exp(- xj - mi ^2 ),则可以令u(j,i) = a(j,i) / sum_j a(j,i) - For i from 1 to k
- 用所有样本点对于聚簇i计算得的模糊质心替换mi--
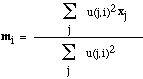
- end_for
-
- end_until
算法的优点是它可以很自然的处理聚簇中的有争议点的值,因此可以很自然的说x有40%的几率属于聚簇1,有60%的几率属于聚簇2,而不是把x完全的属于其中一个聚簇。 其中从属度也可以被解释为概率里面的x属于聚簇i的后验概率的平方根。
流式k-means
这种算法是每次对一个样本点进行聚类时就更新质心,而不是全部样本点聚类完成再进行质心的更新。这种计算对于时序点能够处理的很好,并且能够在我们得到所有样本点之前就运行程序。以下是一个流式k-means:
决定初始质心m1, m2, ..., mk
设置计数器n1, n2, ..., nk为0
Until interrupted
获取下一个样本点x
If mi离x最近
增加ni
用mi + (1/ni)*( x - mi)替换mi
end_if
end_until
很明显mi是所有已经加入聚类i的所有样本点的平均值。 这也表明我们每次更新计数器用的都是常数。特别的,假设a是一个0到1之间的常数,则有如下算法:
决定初始质心m1, m2, ..., mk
Until interrupted
获取下一个样本点x
If mi离x最近
用mi + a*( x - mi )代替mi
end_if
end_until
熟悉DSP的人肯定会说我们用低通滤波操作替换了均值操作。于是我们可以把这个算法叫做“遗忘”流式k-means。不难看出,mi是靠近mi的样本点的加权平均值,权重是以指数的方式随着样本的“年龄”减少的。更确切的说,如果mo是mi的初始值并且如果xj是n个样本点中第j个用来聚类的,那么不难看出:
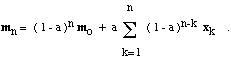 因此,初始值mo最终会被遗忘,并且最近的样本点将比老的样本点得到更高的权重。这种算法能够更简单的实现,并且也更适用于随着时间有变化的问题并且样本点会“移动”的情况。
因此,初始值mo最终会被遗忘,并且最近的样本点将比老的样本点得到更高的权重。这种算法能够更简单的实现,并且也更适用于随着时间有变化的问题并且样本点会“移动”的情况。
总结
- 每种算法都有各自适用的范围,根据具体问题进行修改算法是很有必要的,有时候甚至将算法核心部分重构也无可厚非。
- 三种
k-means算法都没有给出初始质心选取的方案,这个问题也是k-means的一大问题,网络上有很多方案是关于初始质心选取的,本篇文章不再给出,然而笔者也并没有时间再多做总结介绍。 - 没写完的博客不能拖太长时间,这篇博客从创建写了一点之后就再也没动过,今天想起来写点的时候当初很多要写的东西和注意的点居然都想不起来了~
参考文献:
